
Netatmo's Vision and Artificial Intelligence Team main goal is to develop fast and efficient algorithms dedicated to a fine analysis of indoor and outdoor scenes recorded by the cameras of the Netatmo Security range while preserving user data privacy. In 2015, Netatmo launched its Netatmo Security Indoor Camera, followed in 2016 by its Netatmo Outdoor Camera. These two cameras are capable of analysing the scene, filtering out significant events so as to notify the user only of important information: a person's movement, a vehicle, an animal, face detection and recognition, etc. In 2020, the Netatmo Smart Video Doorbell completes the range. Behind the development of these algorithms, there is a continuous study of the state of the art of image analysis techniques in order to select and adapt ideas and methods to the specific requirements of our products.
Fast and efficient edge machine learning algorithms
Netatmo focuses on developing efficient and responsive products while respecting privacy, which is an important issue, especially for security cameras. In particular, this implies that calculations must be carried out on the product (user data is stored on the SD card locally, no data will be processed in the cloud). The final solutions must therefore respect the limits imposed by the capacities of the camera components.
Going deeper in the analysis of the scene
All our cameras focus on scene analysis, using computer vision and image processing algorithms. These algorithms can detect movement in the scene and characterise that movement precisely. For example, with the Smart Outdoor Camera we seek to inform whether a person, animal or vehicle is moving.
The first step of our analysis is based on the detection of the movement of the scene, which is a relatively simple task for the human eye but is more complex to perform automatically, since the intensity of the pixels throughout a video is very sensitive and can change even with insignificant movement, such as changes in light for example. Several techniques exist, more or less fast, more or less "greedy" in memory. We decided to select a technique that combines robustness and speed.
Once motion has been detected, the most complex part remains to be processed: what object is moving? Object recognition and detection are essential tasks in computer vision. The main idea is to find a more "compact" representation of the object than its image, which will be used by a so-called machine learning algorithm, which will learn, via several examples of different classes to assign to each image their corresponding object category. This process is similar to the natural learning process, for example, such as a baby to whom we would have shown several photos of a cat before he was able to identify a cat among other animals on his own.
The quick and constant evolution of machine learning techniques
Until the early 2010s, the representation of images was mainly defined by "hand-crafted" methods. Thus, the object could be represented by information such as its texture, edges, or salient points of objects for example. This mathematical representation is called the "descriptor" of the image and therefore aims to condense all the information necessary to describe the object, just as the human brain would be able, for example, to extract the main features of one face to distinguish it from another (glasses, long hair, an oval face, etc.) However, these techniques have limitations, especially on complex tasks, where the level of abstraction requires finer representations.
Gradually, thanks to the increase in the computing power of computers, and the increasing availability of millions of images on the Internet, techniques called "deep learning" appeared. These techniques are based on the use of neural networks, imitating the behaviour of the human brain: they are composed of several successive layers of neurons, which will process the input image in order to extract a representation allowing proper distinction between the different classes of images (for example between animals and humans). These networks, via a "training" phase that consists of giving as an input a set of images as well as their classes, learn to predict the right category. When the network fails to correctly classify an example, it can correct itself and adjust the parameters of the different layers of neurons in order to fix its mistake. These networks contain millions of neurons and require many examples to achieve good accuracy. As shown in Figure 1, these techniques outperform hand-crafted techniques and even exceed the human performance on the ImageNet competition which is the reference competition for object classification.
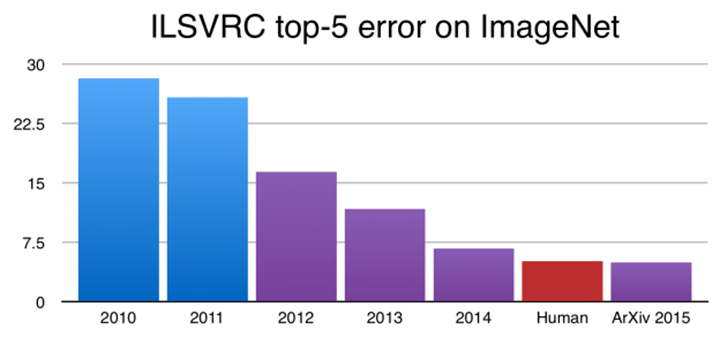
Figure 1: Evolution of the error rate on the ImageNet competition (https://developer.nvidia.com)
What about Netatmo?
At the launch of the security range with the Netatmo Indoor Camera, these deep learning techniques were relatively new and required a lot of data and the existing networks were extremely cumbersome and slow (each example must be fed to the successive layers of neurons before being assigned to human, car or animal class), as depicted in Figure 2.
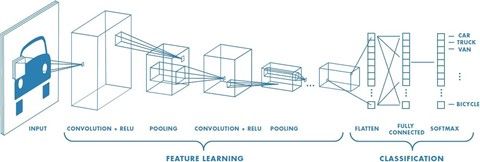
Figure 2: Example of convolutional neural networks (https://towardsdatascience.com)
In addition, the choice to guarantee the respect of customer data implies on-device algorithm execution. Our products are intended for the general public, the available hardware (memory and computing capacity) is limited due to the production cost constrain and therefore has an impact on the neural network selection (some networks took several seconds to be executed, which does not fit the required responsiveness expected from security products). Since 2016, especially for the release of the Smart Outdoor Camera, Netatmo's Vision team has focused its efforts on the creation and adaptation of Deep Learning techniques in order to provide robust and fast algorithms, whether for motion characterization or facial recognition.
Due to the constraint of computing capacity, the team has studied the different existing networks, adapted them to achieve "homemade" networks and developed complex mechanics to guarantee good responsiveness (especially for the floodlight monitoring in the event of human or vehicle movement).
Continuous improvement thanks to user feedback
The networks have been trained and finetuned, thanks in particular to user feedback, which has improved the user experience. Indeed, to validate a new network, the team has a database of labelled validation images to estimate the performance of the algorithms. However, this database does not represent all the possible scene configurations. The customer feedback via the application, such as reporting false classification or detection, is crucial to allow regular updates of the algorithms: if you have agreed to be part of the product improvement program, every time you report a false detection, you participate in the improvement not only of your camera but also of cameras of all users. The more the algorithm is challenged with its mistakes, the more it will be able to correct them.
Continuous integration of new techniques
Between the release of the Netatmo Outdoor Camera and the Netatmo Smart Video Doorbell, the techniques evolved very quickly and part of the literature gradually focused on the problem of embedded execution.
Techniques such as network pruning (reducing the size of networks) or quantification (allowing the acceleration of calculations on machines) have reduced the execution time of existing networks, and several works have focused on the development of lightweight and efficient networks while guaranteeing stability on performance. The complete analysis of the scene (instead of being object by object) could be done in a short time and we took into account this evolution for the implementation of human detection on the Netatmo Smart Video Doorbell, which made it possible to develop a lightweight model, capable of meeting the challenge of embedded computing on this product. This improvement has led us to evolve our algorithms on the Netatmo Outdoor Camera. Thus, we deployed these new techniques on the Netatmo Outdoor Camera, leading to:
A complete analysis of the scene, between two and three times faster.
More precise delineation of objects, the previous algorithms being very dependent on motion
This improved delineation allows better tracking of objects and the implementation of an efficient technique to filter out "false" objects in motion.
Conclusion
Our smart cameras incorporate unique technologies that are always as close as possible to the state of the art in image analysis, and we make sure that we integrate these new techniques as we go along to provide the user with a better experience thanks to faster and more efficient algorithms. Because these cameras are connected, even years after their release, they will still be able to benefit from the evolution of the technology, making it possible for improvements or even the introduction of new features!