
L’équipe Vision et Intelligence Artificielle de Netatmo a pour mission de développer des algorithmes rapides et efficaces pour assurer une analyse fine des scènes filmées par les caméras de la gamme Sécurité, tout en préservant les données des utilisateurs. En 2015, Netatmo lance sa Caméra Intérieure Intelligente, suivie en 2016 par sa Caméra Extérieure Intelligente. Ces deux caméras sont capables d'analyser la scène, filtrer les événements significatifs de façon à notifier à l’utilisateur seulement les informations d’importance : mouvement d’une personne, d’un véhicule, d’un animal, détection et reconnaissance de visages... En 2020, la Sonnette Vidéo Intelligente vient compléter la gamme. Derrière le développement de ces algorithmes, il existe une étude continue de l’état de l’art des méthodes d’analyse d’images afin de sélectionner et d’adapter des idées et des méthodes aux contraintes spécifiques de nos produits.
Des algorithmes rapides et efficaces dans un environnement embarqué
Netatmo se concentre sur le développement de produits efficaces et réactifs, tout en respectant la vie privée, ce qui représente un enjeu important en particulier pour des caméras. Ceci implique notamment que les calculs doivent être effectués sur le produit (les données utilisateurs sont stockées sur la carte SD localement, aucune donnée ne sera traitée sur le cloud). Les solutions envisagées doivent donc respecter les limites imposées par les capacités des composants des caméras.
Aller plus loin dans l’analyse de la scène : quels algorithmes ?
Toutes nos caméras se concentrent sur l’analyse de la scène, grâce à des algorithmes de vision par ordinateur et de traitement d’images. Ces algorithmes sont capables de détecter les mouvements dans la scène, et de caractériser précisément ce mouvement. Dans le cas de la Caméra Extérieure Intelligente nous cherchons à informer s’il s’agit d’une personne, d’un animal ou d’un véhicule qui est en mouvement.
La première étape de notre analyse, repose sur la détection du mouvement de la scène, qui représente une tâche relativement simple pour l’œil humain, mais qui est en réalité plus complexe à réaliser automatiquement, car l’intensité des pixels tout au long d’une vidéo est très sensible et peut changer même dans le cas de mouvement non significatif, tel que des changements de lumière par exemple. Plusieurs techniques existent, plus ou moins rapides, plus ou moins “gourmandes” en mémoire. Il a fallu sélectionner la technique alliant robustesse et rapidité.
Une fois le mouvement détecté, la partie la plus complexe reste à être traitée : quel objet est en mouvement ? La reconnaissance et la détection d’objet sont des tâches essentielles en vision par ordinateur. L’idée principale est de trouver une représentation plus “compacte” de l'objet que son image, c’est elle qui va être exploitée par un algorithme dit d’apprentissage (de machine learning), qui va apprendre, via plusieurs exemples de différentes classes à attribuer à chaque image leur classe d’appartenance. Ce processus s’apparente au processus naturel d’apprentissage, comme un bébé à qui on montrerait plusieurs photos de chat avant qu’il soit capable lui-même d’identifier un chat parmi d’autres animaux par exemple.
Des algorithmes en constante évolution
Jusqu’au début des années 2010, la représentation des images était principalement définie par des méthodes “à la main” par les chercheurs et ingénieurs. Ainsi, l’objet pouvait être représenté par des informations telles que sa texture, ses contours, ou des points saillants des objets par exemple. Cette représentation mathématique est appelée “descripteur” de l’image et a donc pour but de condenser toutes les informations nécessaires pour décrire l’objet, tout comme le cerveau humain serait capable, par exemple, d’extraire les traits principaux d’un visage pour le distinguer d’un autre (il a des lunettes, des cheveux longs, le visage ovale...) Cependant ces techniques connaissent des limites, notamment sur des tâches complexes, où le niveau d’abstraction requiert des représentations plus fines.
Petit à petit, grâce à l’augmentation de la puissance de calculs des ordinateurs, et la disponibilité de plus en plus grandes de millions d’images sur internet, des techniques appelées “deep learning” sont apparues. Ces techniques se basent sur l’utilisation de réseaux de neurones, imitant le comportement du cerveau humain : ils sont composés de plusieurs couches successives de neurones, qui vont traiter l’image d’entrée afin d’en extraire une représentation permettant une bonne discrimination entre les différentes classes d’images (par exemple entre animaux et humain). Ces réseaux, via une phase “d’entraînement” qui consiste à donner en entrée un ensemble d’images ainsi que leurs classes, apprennent à prédire la bonne catégorie. En cas d’erreur, le réseau va pouvoir corriger et ajuster les paramètres des différentes couches de neurones afin de correctement classer l’exemple. Ces réseaux comportent des millions de neurones, et nécessitent beaucoup d’exemples pour arriver à une bonne précision. Comme le montre la figure 1, ces techniques ont permis de faire exploser les performances par rapport aux techniques traditionnelles d’extraction à la main, jusqu’à dépasser les performances humaines sur la compétition ImageNet qui est la compétition de référence pour la classification d’objet.
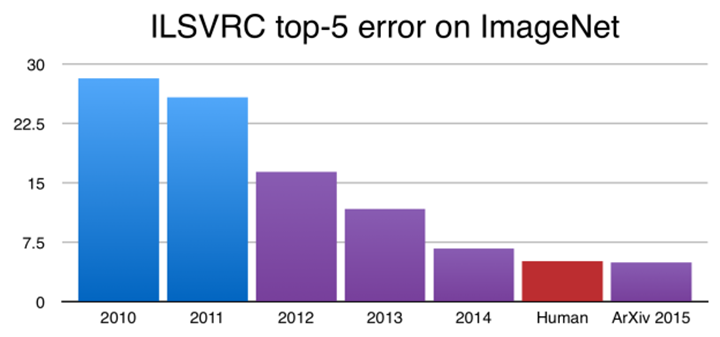
Figure 1 : Evolution du taux d’erreur sur la compétition ImageNet (https://developer.nvidia.com)
Et Netatmo dans tout ça ?
Au lancement de la gamme de sécurité avec la Caméra Intérieure Intelligente, ces techniques de Deep Learning étaient relativement récentes et demandaient beaucoup de données et les réseaux associés étaient extrêmement lourds et lents (chaque exemple doit passer les différentes couches de neurones avant de se voir attribuer sa classe humain, voiture ou animal).
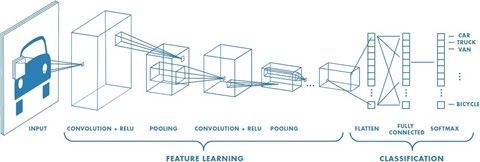
Figure 2 : Exemple de réseaux de neurones convolutionnels (https://towardsdatascience.com)
De plus, le choix de garantir le respect des données clients, nous impose de mettre en place des algorithmes dont l’exécution est réalisée sur le produit. La Caméra Intérieure Intelligente (et celles qui suivirent) étant destinée au grand public, et par contrainte de respect de coût, le hardware disponible (mémoire et capacité de calcul) nous limitait dans la mise en place de ces algorithmes (certains réseaux mettaient plusieurs secondes à être exécutés, ce qui ne permet pas la réactivité voulue pour des produits de sécurité). A partir de 2016, notamment pour la sortie de la Caméra Extérieure Intelligente, l’équipe Vision de Netatmo a concentré ses efforts sur la création et l’adaptation de techniques de Deep Learning afin de proposer un algorithme robuste et rapide, que ce soit pour la caractérisation du mouvement ou la reconnaissance faciale.
Du fait de la contrainte de capacité de calcul, l’équipe a ainsi étudié les différents réseaux disponibles, et les a adaptés afin d’aboutir à des réseaux “faits maison” et une mécanique complexe permettant de garantir une bonne réactivité (notamment pour l’allumage du projecteur la nuit en cas de mouvement personne/humain ou véhicule).
Une amélioration permanente possible grâce aux retours utilisateurs
Les réseaux ont été entraînés et affinés, grâce notamment aux retours utilisateurs ce qui a permis d’améliorer l’expérience utilisateur. En effet, pour valider un nouveau réseau, l’équipe dispose d’une base d’images de validation (dont on connait la catégorie) permettant d’estimer les performances des algorithmes. Cependant cette base ne représente pas l’ensemble des configurations possibles chez les clients. La mise en place de retours clients via l’application, tels que le signalement de fausse classification ou fausse détection, est indispensable pour permettre de proposer régulièrement des mises à jour des algorithmes. En effet, si vous avez accepté de faire partie du programme d’amélioration des produits, à chaque fois que vous signalez une fausse détection, vous participez à l’amélioration non seulement de votre caméra, mais également pour des caméras de l’ensemble des utilisateurs. Plus l’algorithme est confronté à ses erreurs, plus il sera en mesure de les corriger.
Intégration continue de nouvelles techniques
Entre la sortie de la Caméra Extérieure Intelligente et de la Sonnette Vidéo Intelligente (Netatmo Doorbell), les techniques ont évolué très rapidement et une partie de la littérature s’est petit à petit focalisée sur le problème de l'exécution embarquée.
En effet, des techniques comme l’élagage de réseaux (réduction de la taille des réseaux) ou la quantification (permettant l’accélération des calculs sur les machines) ont permis de réduire le temps d’exécution des réseaux existants, et plusieurs travaux se sont concentrés sur l’élaboration de réseaux légers et performants, tout en garantissant une stabilité sur la performance. L’analyse complète de la scène (au lieu de la faire objet par objet) a pu se faire dans un temps réduit et nous avons pris en compte cette évolution pour la mise en place de la détection d’humains sur la Sonnette Connectée, ce qui a permis de développer un modèle léger, capable de relever le défi du calcul embarqué sur ce produit. Cette amélioration nous a mené à faire évoluer nos algorithmes sur la Caméra Extérieure. Ainsi, nous avons déployé ces nouvelles techniques sur la Caméra Extérieure Intelligente, ce qui a permis :
Une analyse complète de la scène, en deux à trois fois moins de temps.
Des délimitations des objets plus précises, les algorithmes précédents étant très dépendants des zones de mouvement.
Cette meilleure délimitation permet un meilleur suivi des objets et la mise en place d’une technique efficace de filtrage de “faux objets” en mouvement.
Conclusion
Nos caméras intelligentes embarquent des technologiques uniques, toujours au plus proche de l’état de l’art de l’analyse d'images, et nous veillons à intégrer au fur et à mesure ces nouvelles techniques afin de faire bénéficier à l’utilisateur d’une meilleure expérience, avec des algorithmes plus rapides et plus efficaces. Ces caméras étant connectées, même plusieurs années après leur sortie, elles pourront encore bénéficier de l’évolution de la technologie, rendant possible des améliorations ou même l’introduction de nouvelles fonctionnalités !